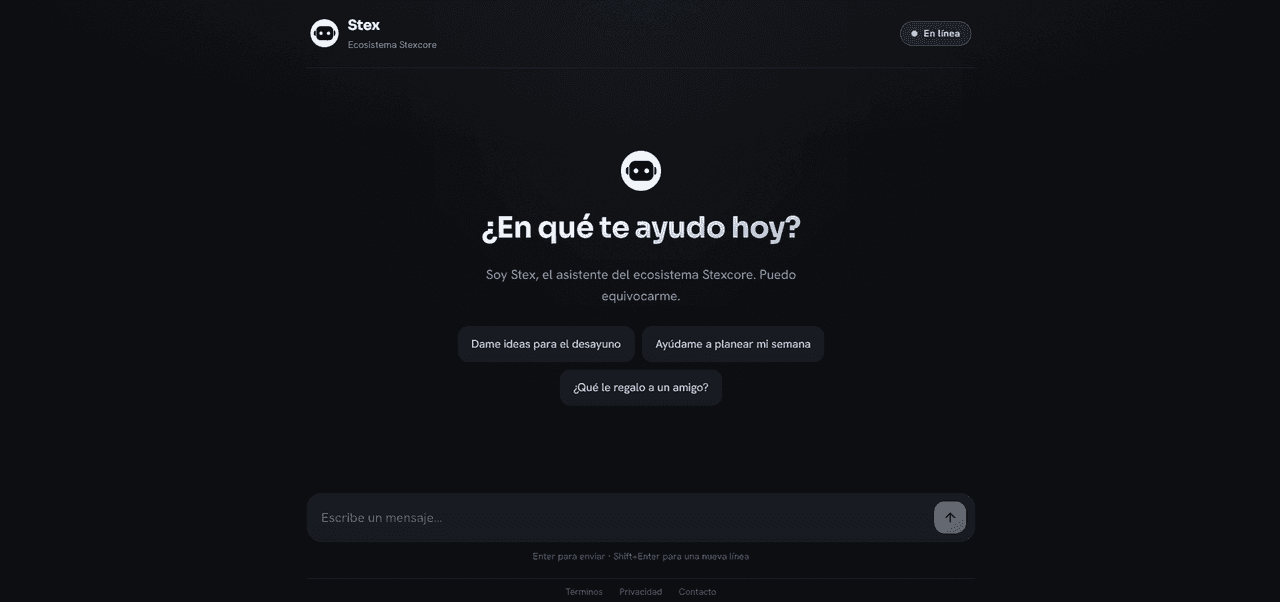
StexAssistant
A private, self-contained AI chat with your own model running locally. StexAssistant ("Stex") is the conversational assistant of the Stexcore Technology ecosystem: a streaming chat experience powered by a local Ollama model, deployed in full with a single command.
In development
✨ What it is
StexAssistant is a privacy-first AI chat: the model runs locally through Ollama, with no dependency on any cloud API. Your conversations never leave for third-party services, because all inference happens inside your own infrastructure.
It is designed as a self-contained piece: a Next.js front-end + an Ollama model bundled together, ready to run with a single docker compose up. The model is chosen entirely through environment variables.
🚀 Key features
- ⚡ Streaming responses: output is rendered token by token, with a typewriter effect.
- 📝 Rich markdown: syntax-highlighted code blocks with a copy button.
- 🔄 Model-agnostic: swap the model by setting
OLLAMA_MODELin the environment — no rebuild required. - 🛡️ Hardened security: CSP, origin checks, per-IP rate limiting, concurrency caps, and an Ollama that is never exposed publicly.
- 🎨 Silver Premium design: shares the visual language of the Stexcore landing.
- 📦 Self-contained: full deployment with a single
docker-compose.
🛠️ Stack
| Layer | Technology |
|---|---|
| Framework | Next.js + React |
| Language | TypeScript |
| Styling | TailwindCSS |
| AI model | Ollama (local) |
| Markdown | react-markdown + remark-gfm |
| Highlighting | highlight.js + rehype-highlight |
| Deployment | Docker / docker-compose |
⚡ Deployment
The whole system (app + model) comes up with a single command:
cp env.example .env # adjust if you like
docker compose up --build
On first boot, the Ollama service downloads the model defined in OLLAMA_MODEL into a persistent volume. Subsequent boots are instant.
📦 Status
In development. StexAssistant is being built within Stexcore Technology, a team based in Venezuela with international clients. The documented domain is chat.stexcore.net.